
We are proud to announce that we have successfully upgraded to Play 2.4.x, “Damiya”. Although the last few Play releases were generally straightforward to upgrade to, with 2.4, the Play team made a lot of big changes to the framework, resulting in a lot of fixes and performance improvements. Some of the changes that are more relevant to Octoparts include:
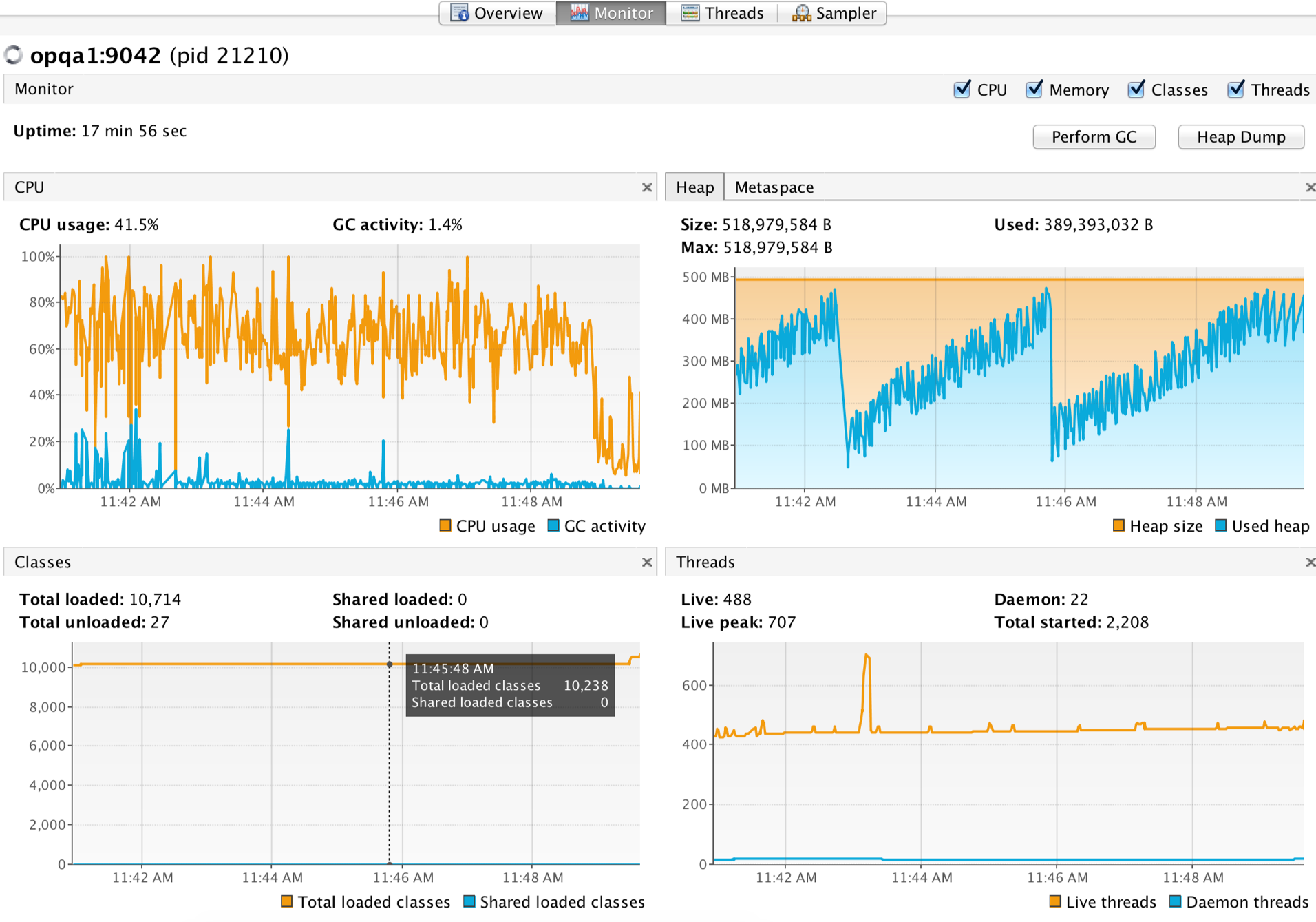
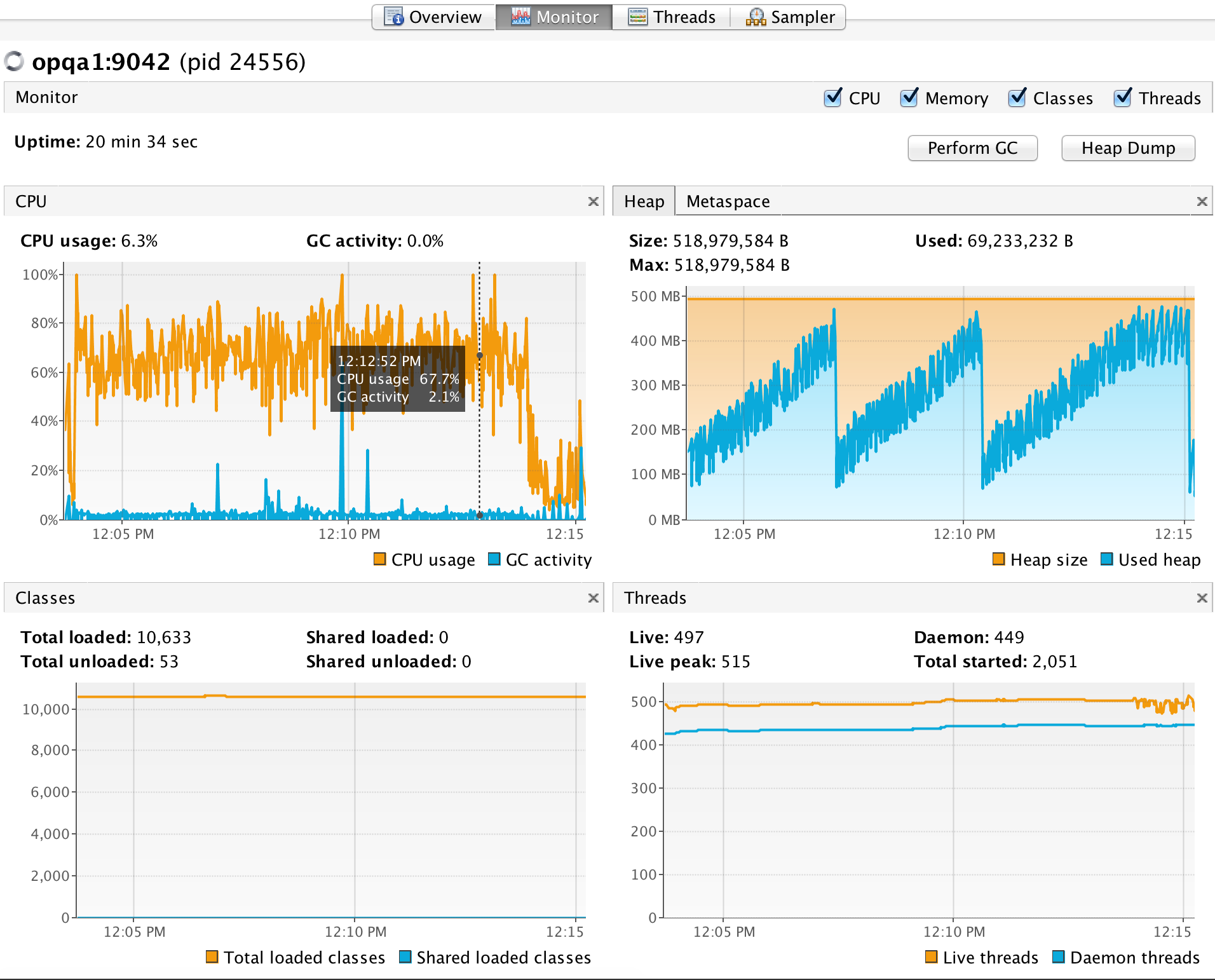
After performing the upgrade, we deployed it into our test and QA environments and carefully monitored it for problems. When we found none, we used Siege to stress test the latest Play 2.3.x-based version of Octoparts against the Play 2.4.x-based version. The following results were obtained from 10 mins of Sieging using a payload equivalent to one that would request data for the M3.com homepage for signed-in users, with 100 concurrent requests, and zero delay on a 2Ghz Corei7 (Haswell) Macbook Pro with 8GB RAM:
| Play 2.3.x based | Play 2.4.x based | |
|---|---|---|
| JVisualVM |
|
|
| Transactions | 24317 hits | 25024 hits |
| Availability | 99.93 % | 100.00 % |
| Elapsed time | 599.44 secs | 598.99 secs |
| Data transferred | 145.70 MB | 149.84 MB |
| Response time | 1.96 secs | 1.89 secs |
| Transaction rate | 40.57 trans/sec | 41.78 trans/sec |
| Throughput | 0.24 MB/sec | 0.25 MB/sec |
| Concurrency | 79.49 | 79.04 |
| Successful transactions | 24317 | 25024 |
| Failed transactions | 16 | 0 |
| Longest transaction | 12.03 secs | 3.19 secs |
| Shortest transaction | 0.06 secs | 0.06 secs |
Overall, there is a slight improvement in response time, and in resource usage under stress (if anything, performance under stress improved because there is a lower tendency to hit 100% CPU usage peaks), with Siege reporting fewer failures (99.93% availability with Play 2.3 version versus 100% availability with Play 2.4). Thanks to Play 2.4’s thread pool optimisation, we are using ~200 less threads at peak than with 2.3.x.